From idea to product:
creating Spare Cores
Gergely Daróczi
Jan 10, 2025
Slides: sparecores.com/talks
>>> from sparecores import why
>>> from sparecores import why
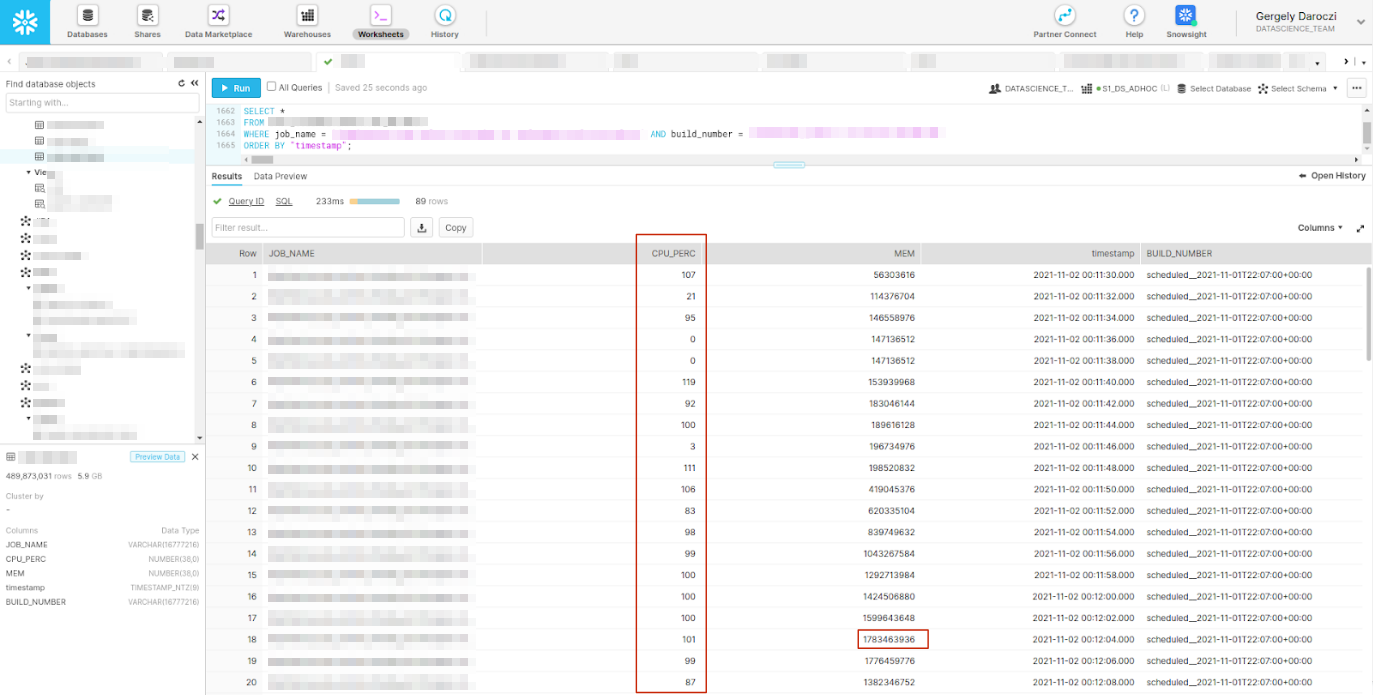
>>> from sparecores import why

AWS ECS

AWS Batch

Kubernetes
>>> from sparecores import why
Source: xkcd
>>> from sparecores import why
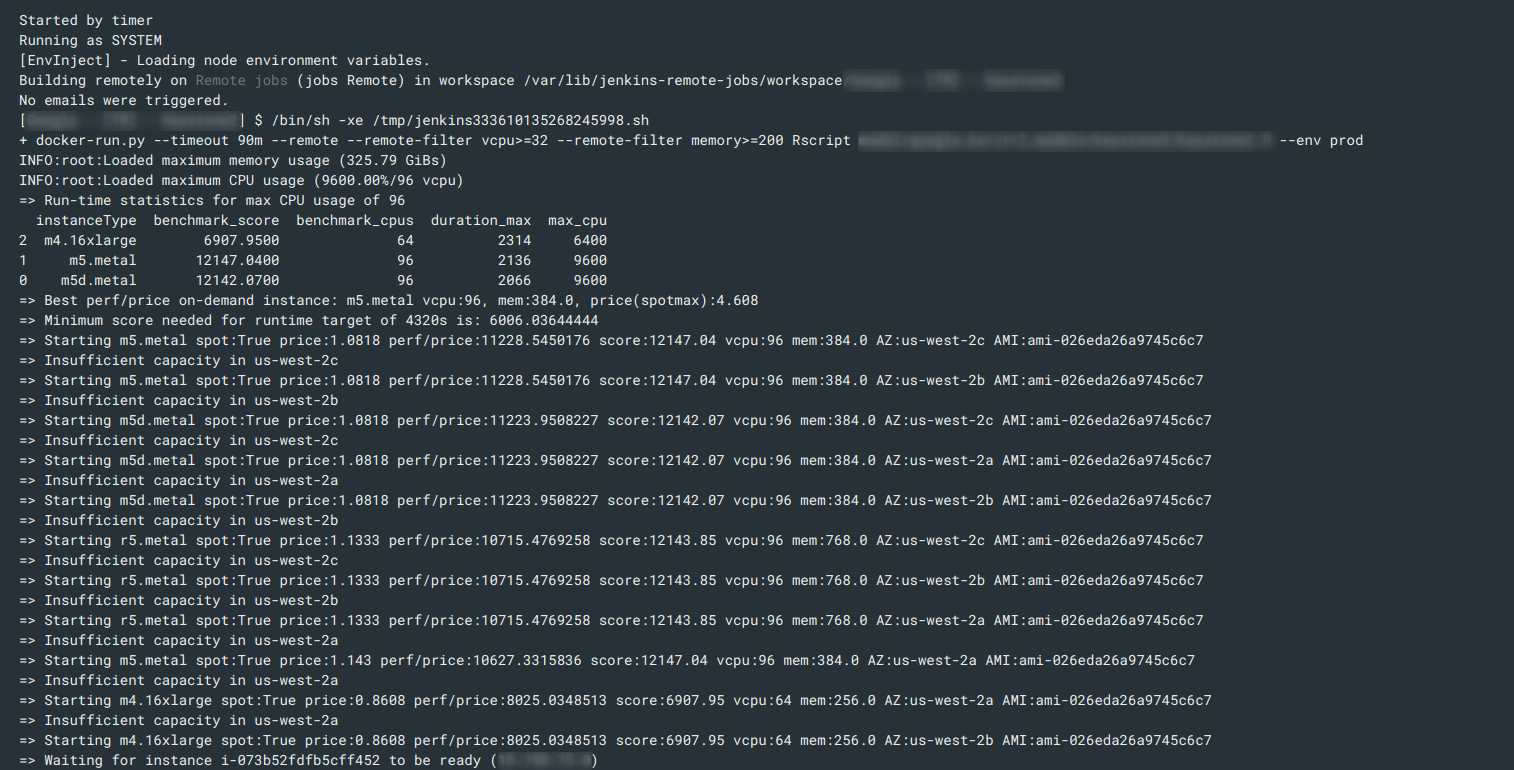
>>> from sparecores import why
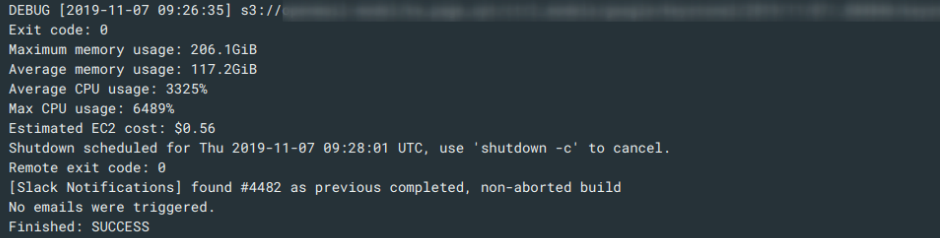
>>> from sparecores import why
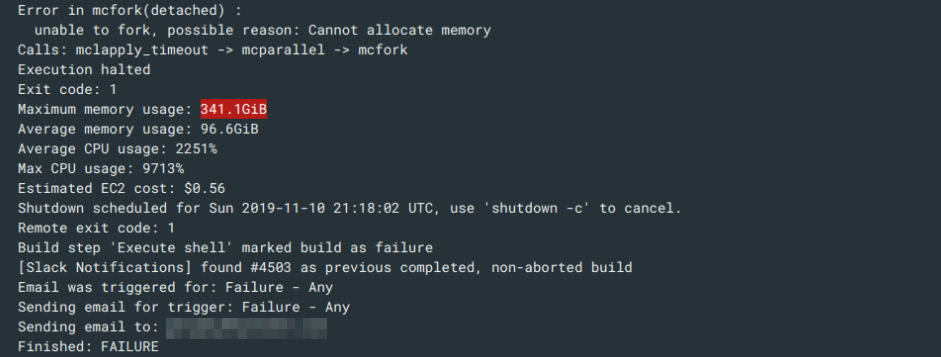
>>> from sparecores import why

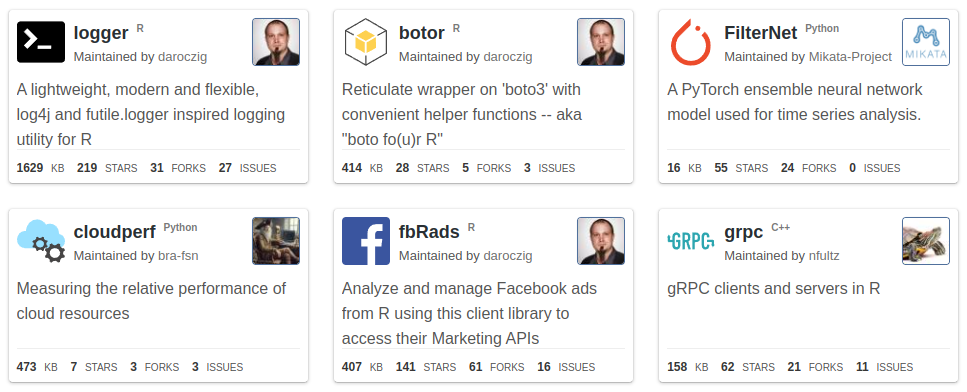
>>> from sparecores import support

>>> from sparecores import intro
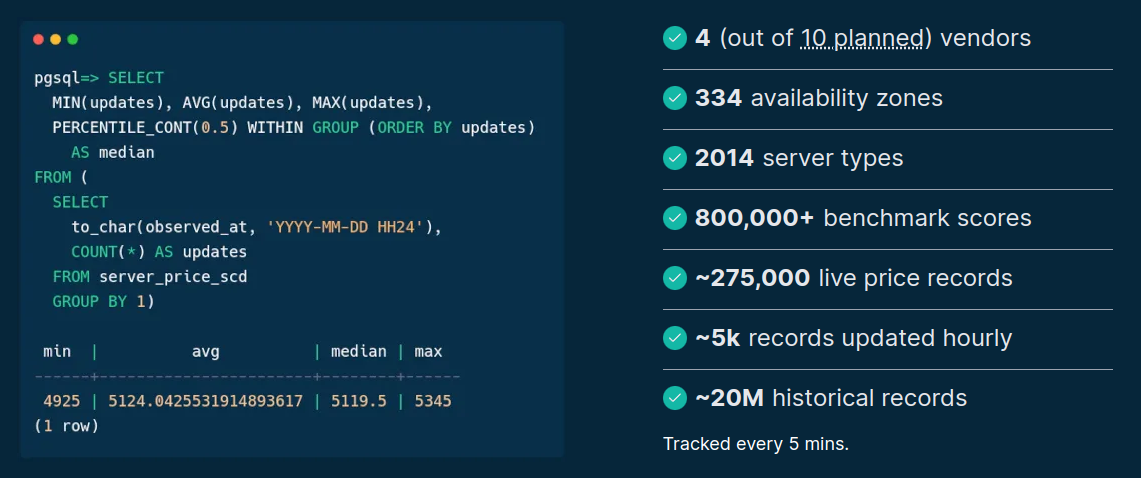
Source: sparecores.com
>>> from sparecores import intro
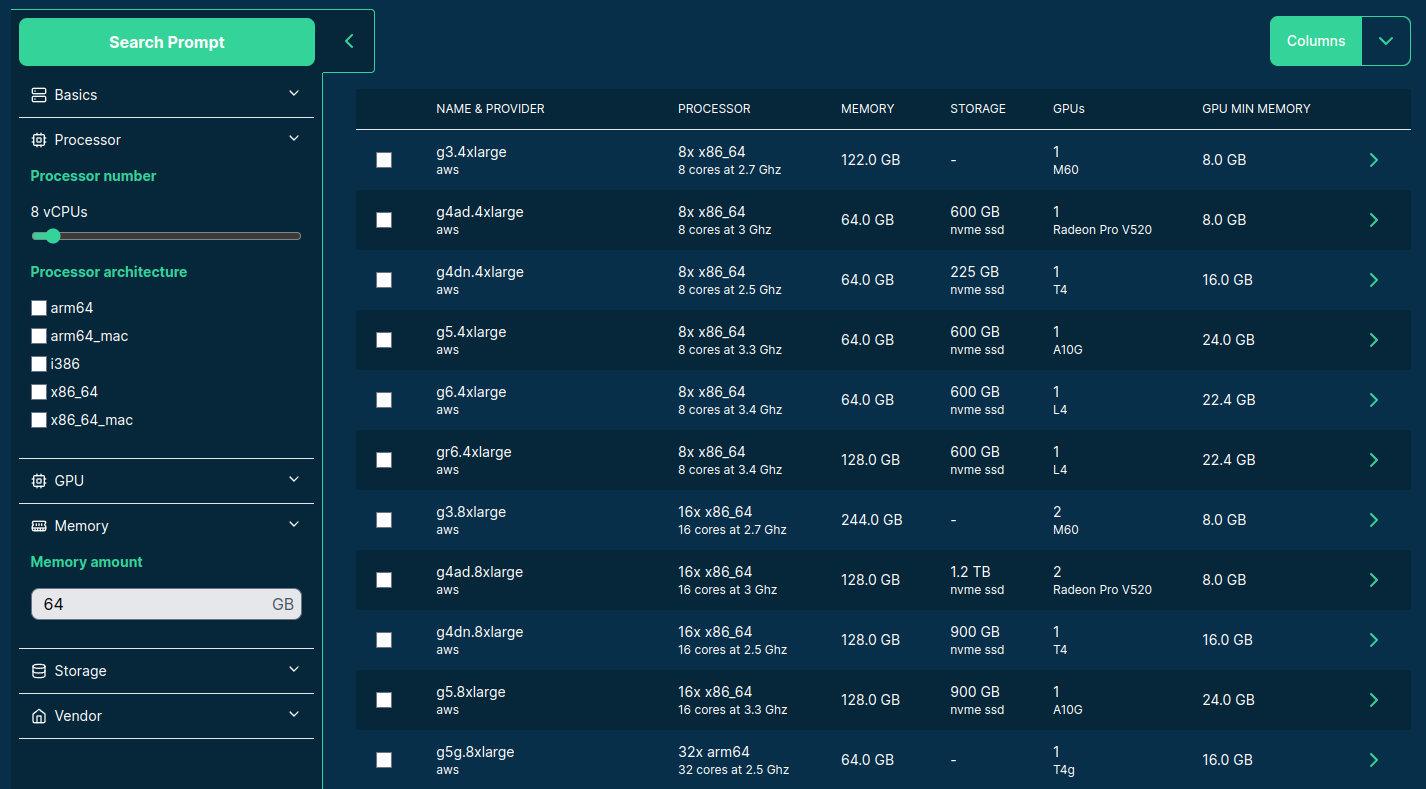
>>> from sparecores import intro
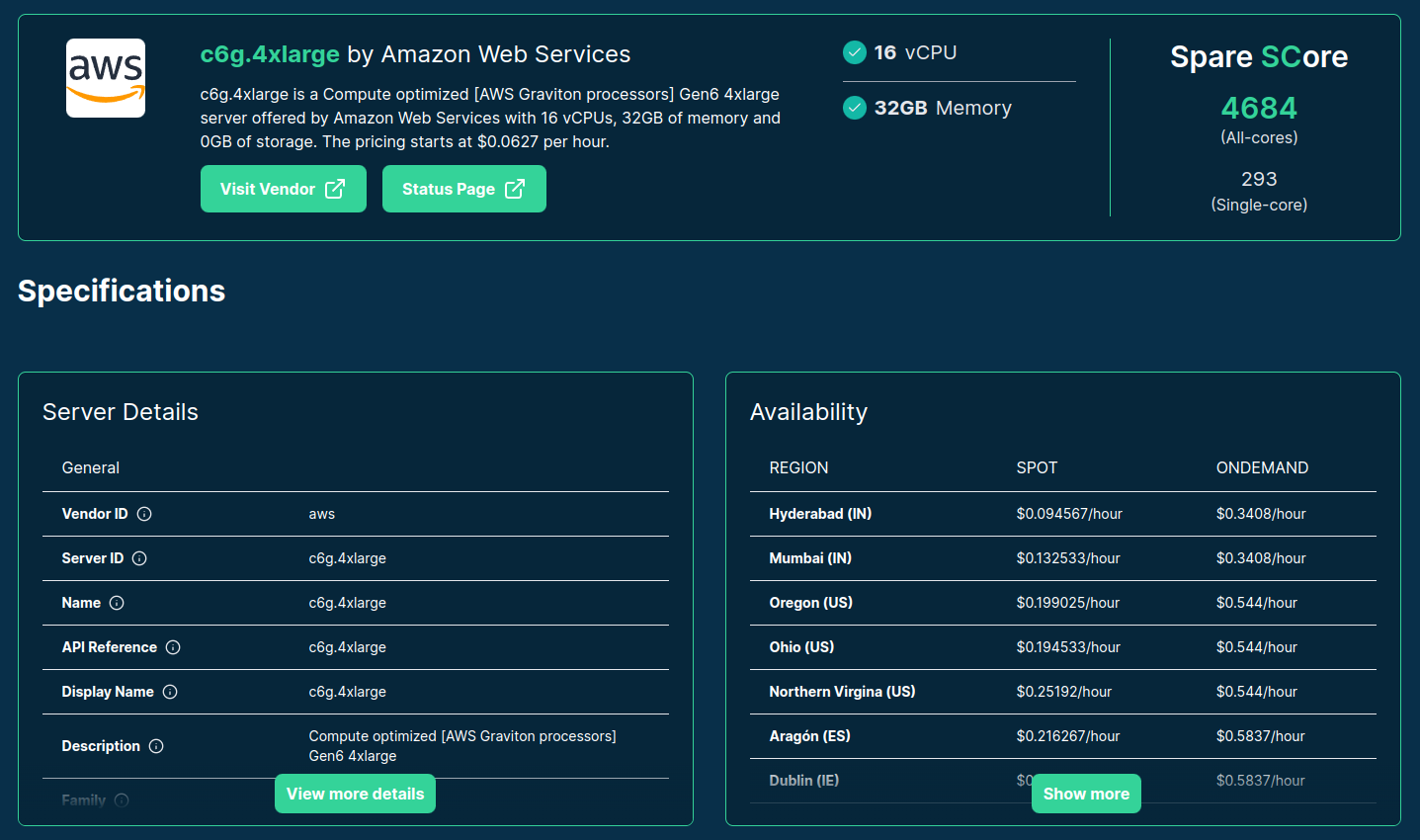
>>> from sparecores import intro
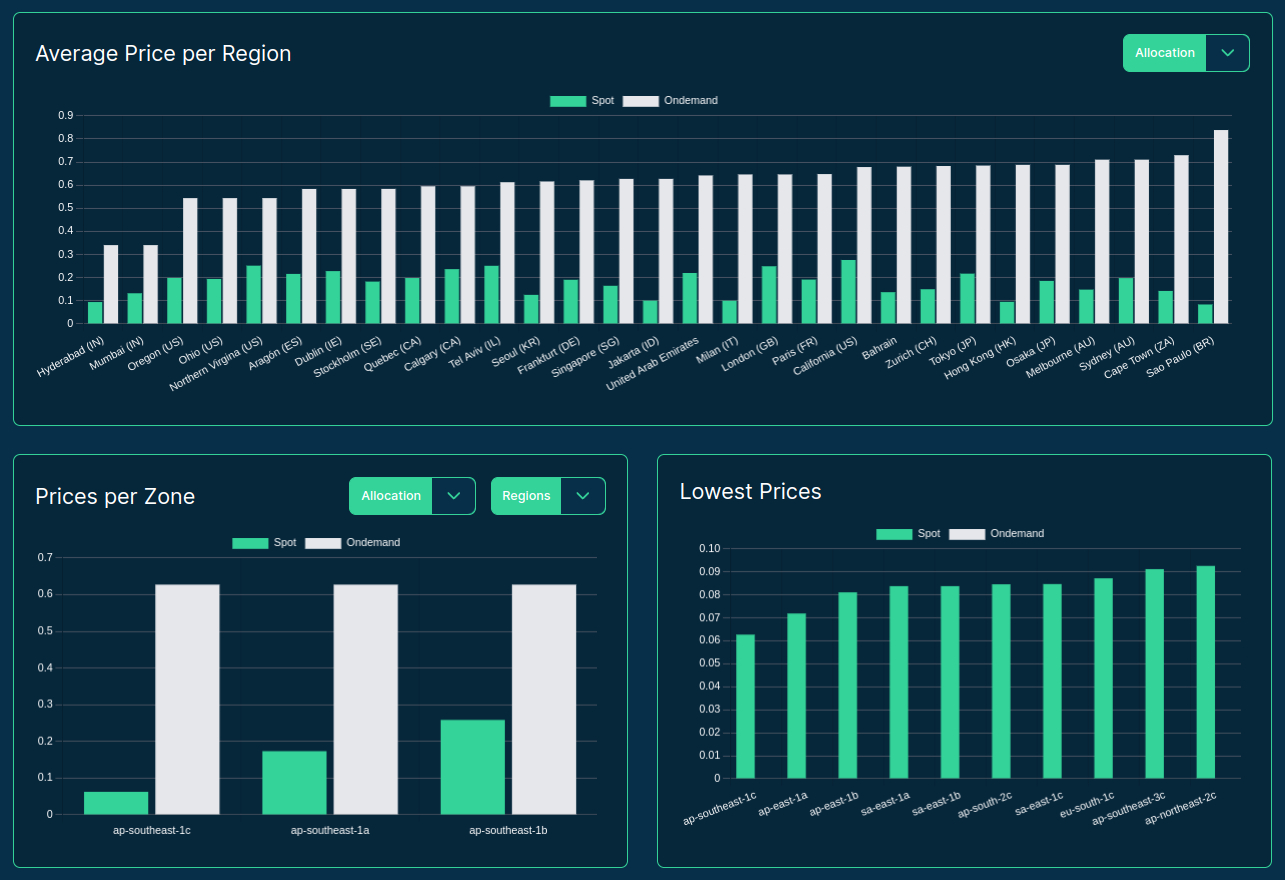
>>> from sparecores import intro
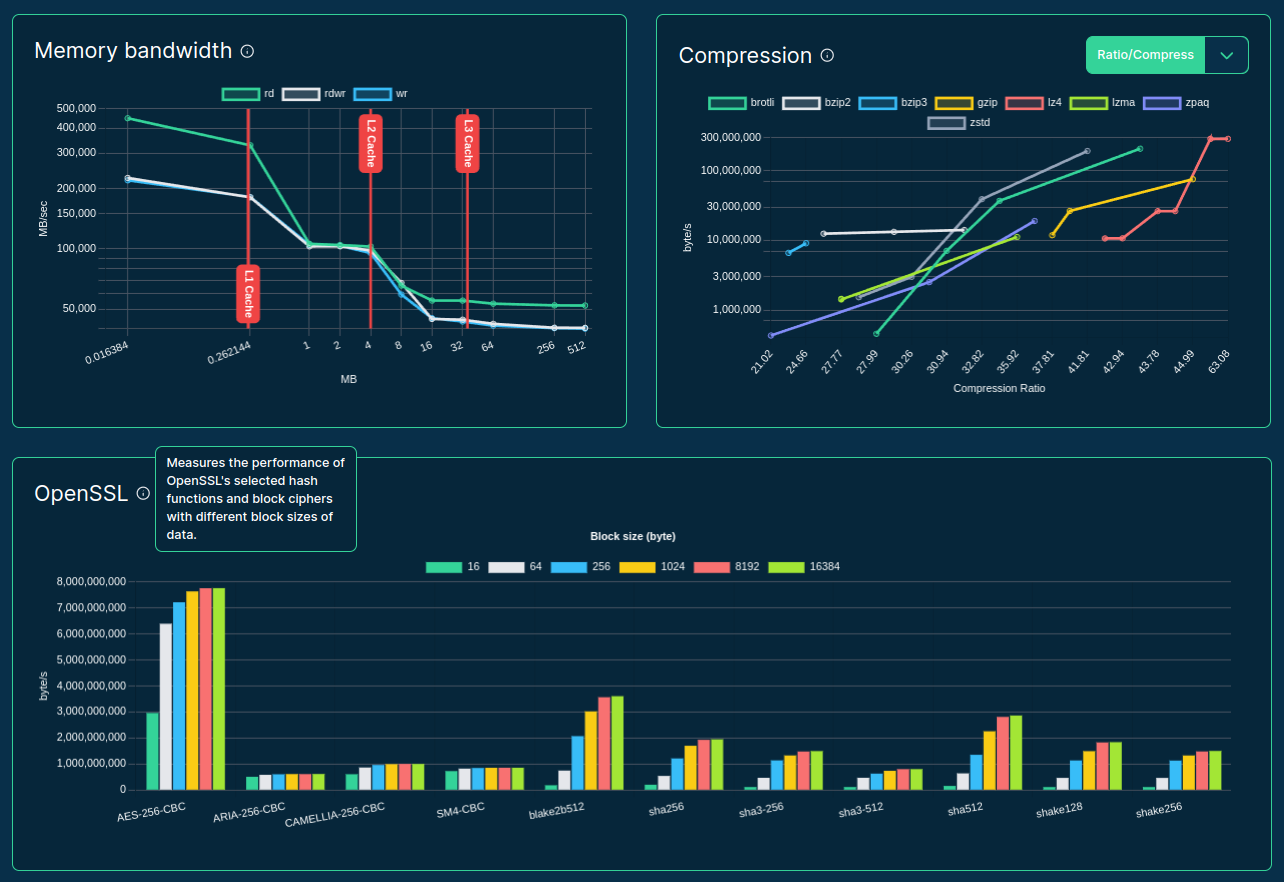
>>> from sparecores import intro
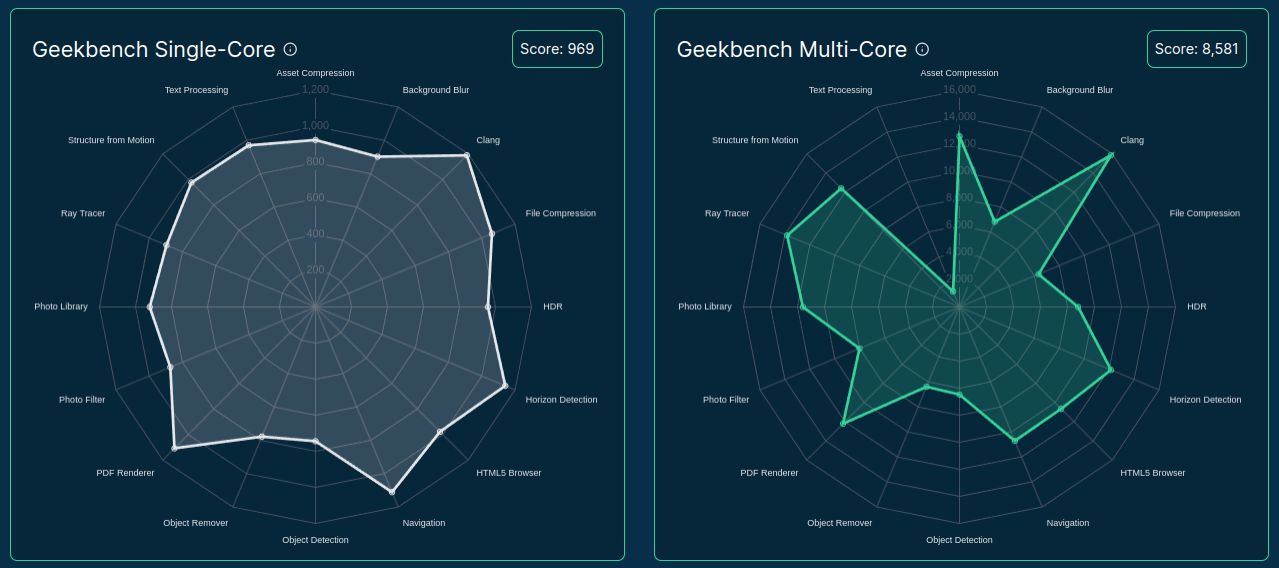
>>> from sparecores import intro
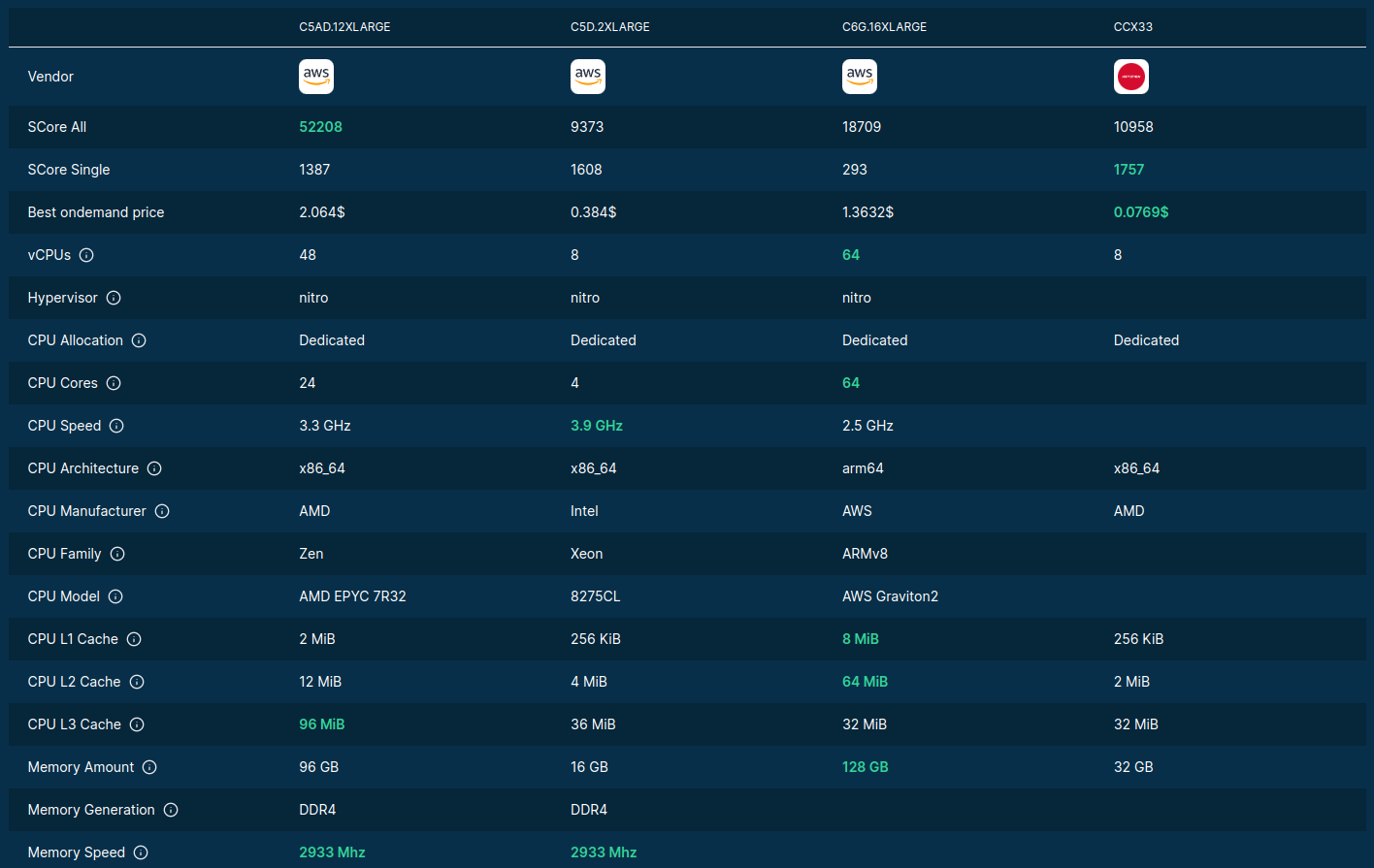
>>> from sparecores import intro
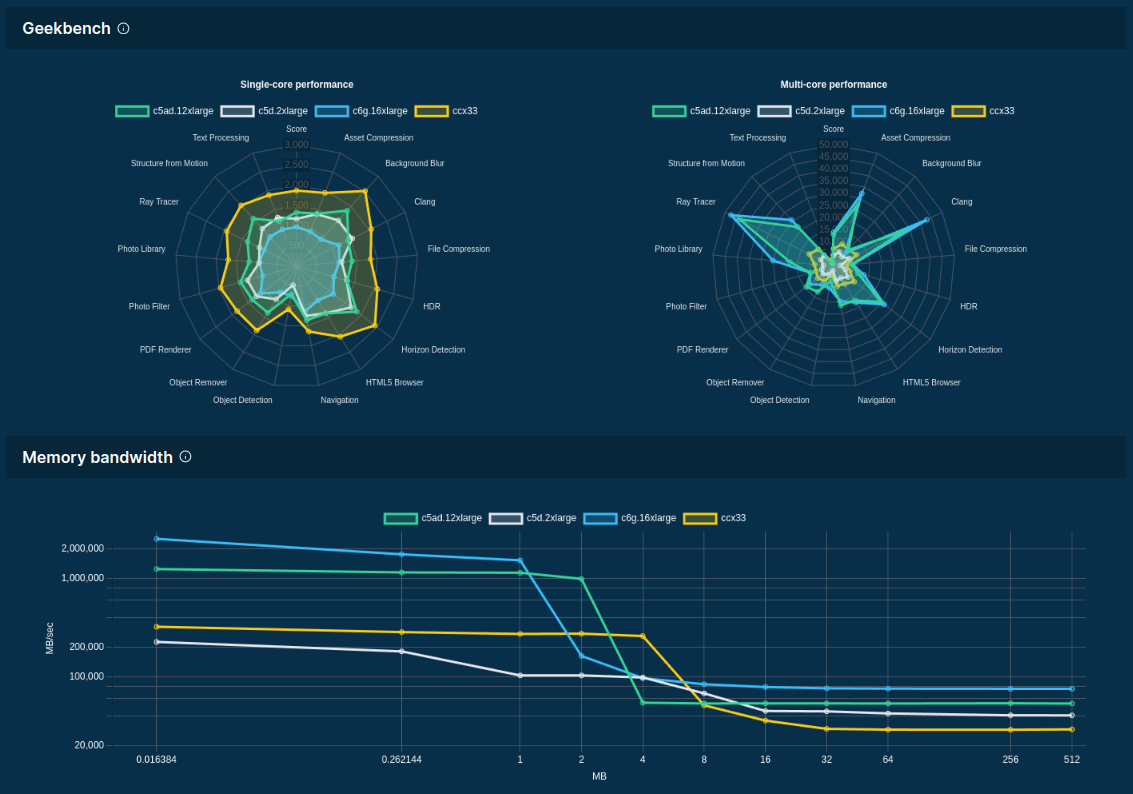
>>> from sparecores import intro
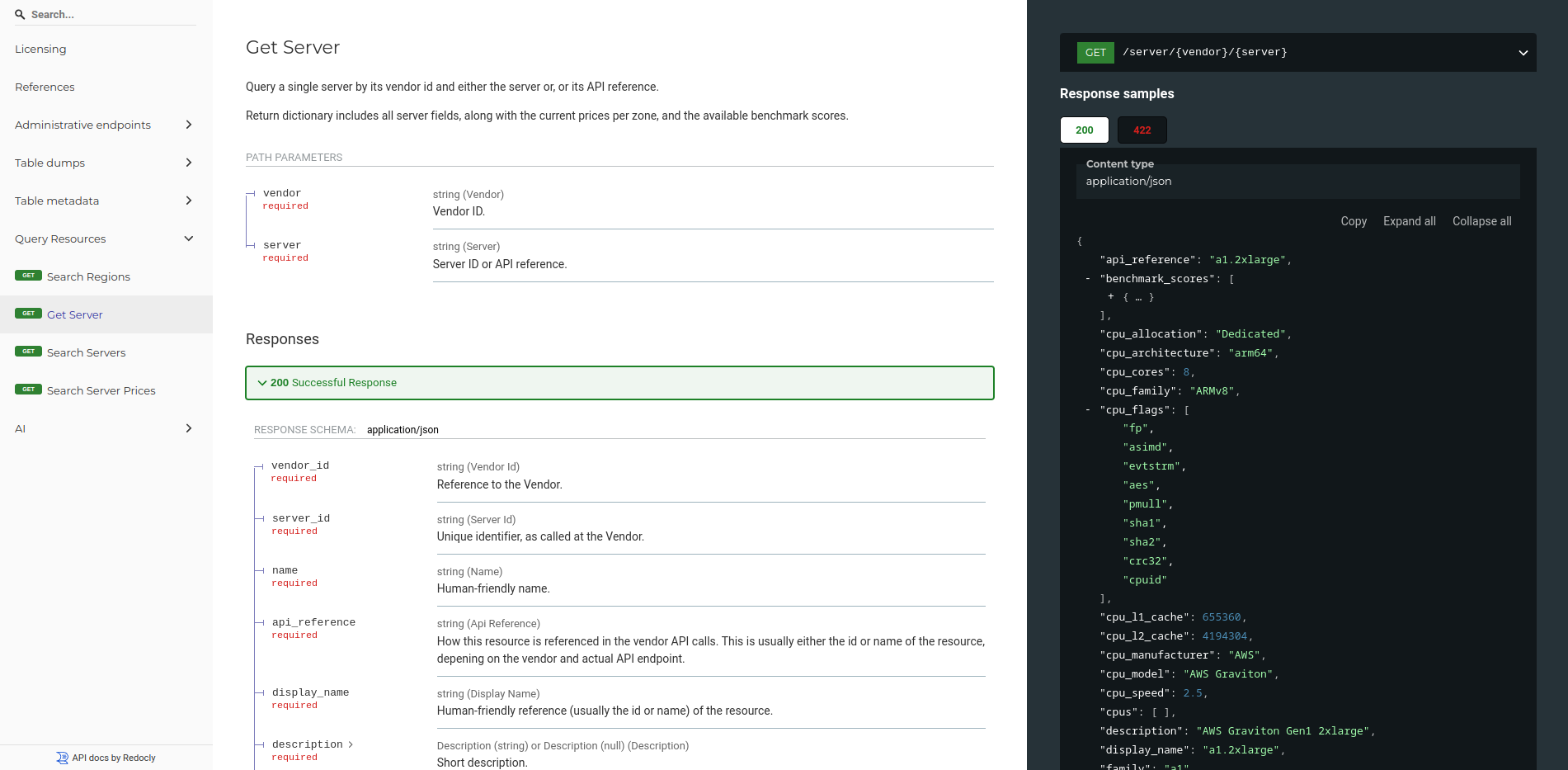
>>> sparecores.__dir__()

>>> input(“Biggest challenge?”)
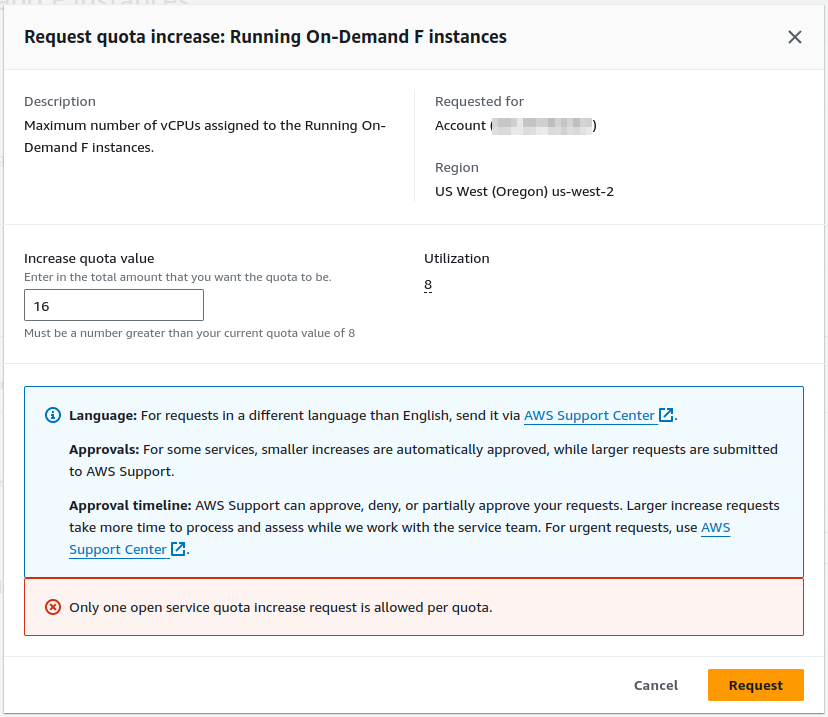
>>> input(“Biggest challenge?”)
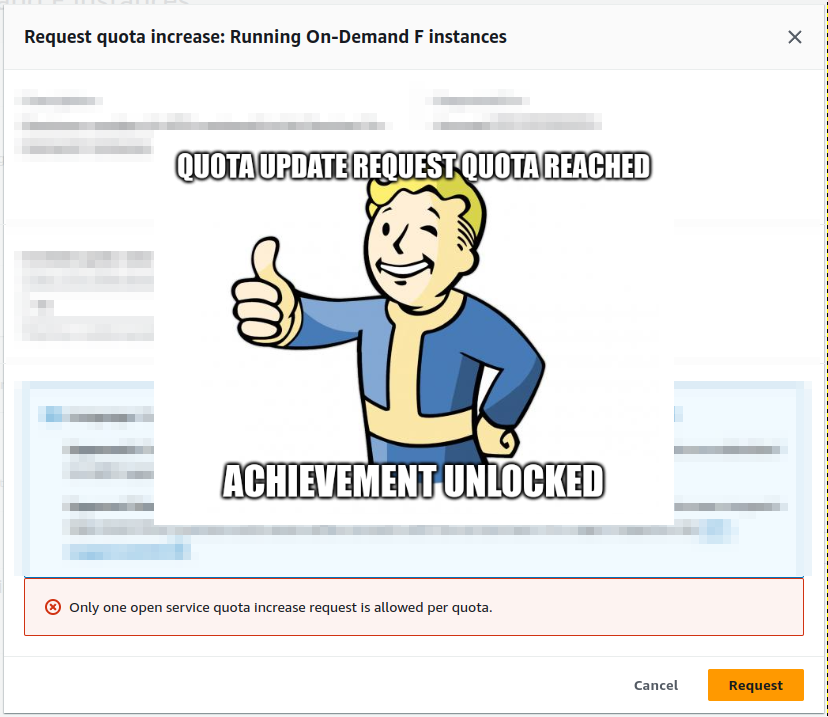
>>> input(“Why not use ChatGPT?!”)

>>> input(“Why not use ChatGPT?!”)

>>> input(“Burned 150k on this?!”)

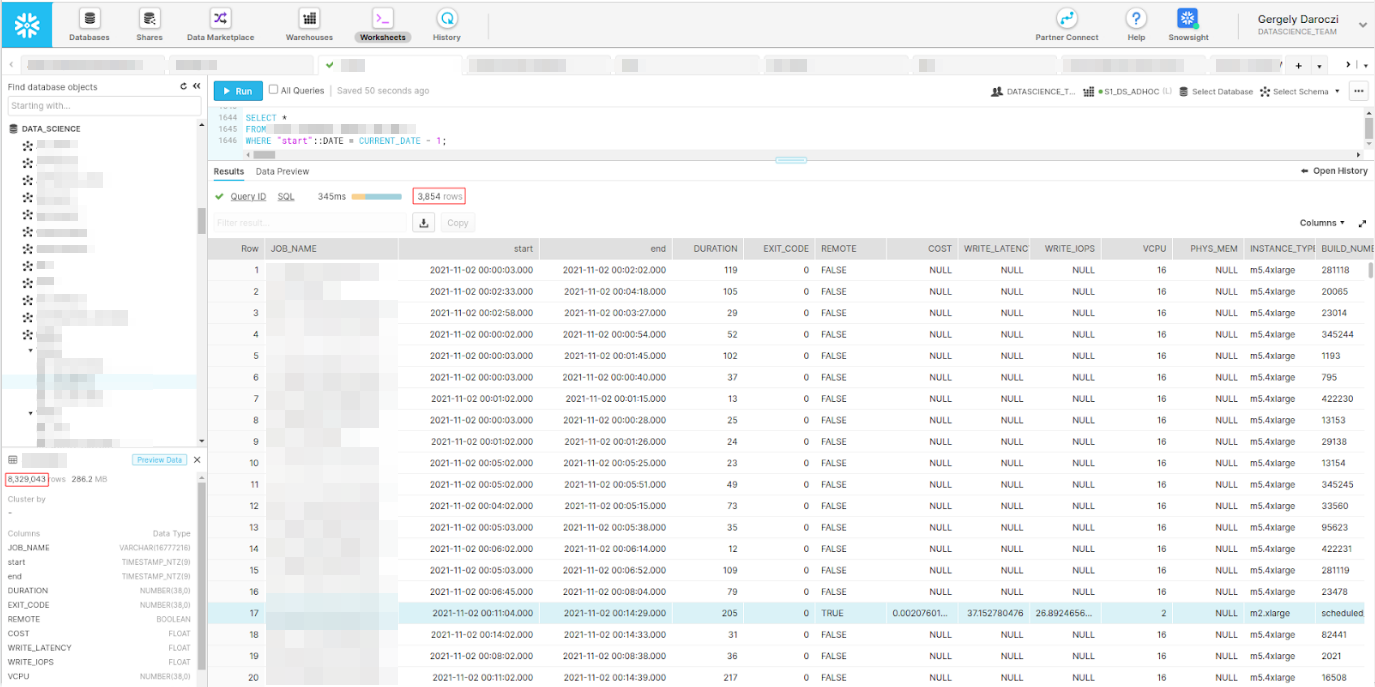
>>> import sc_data
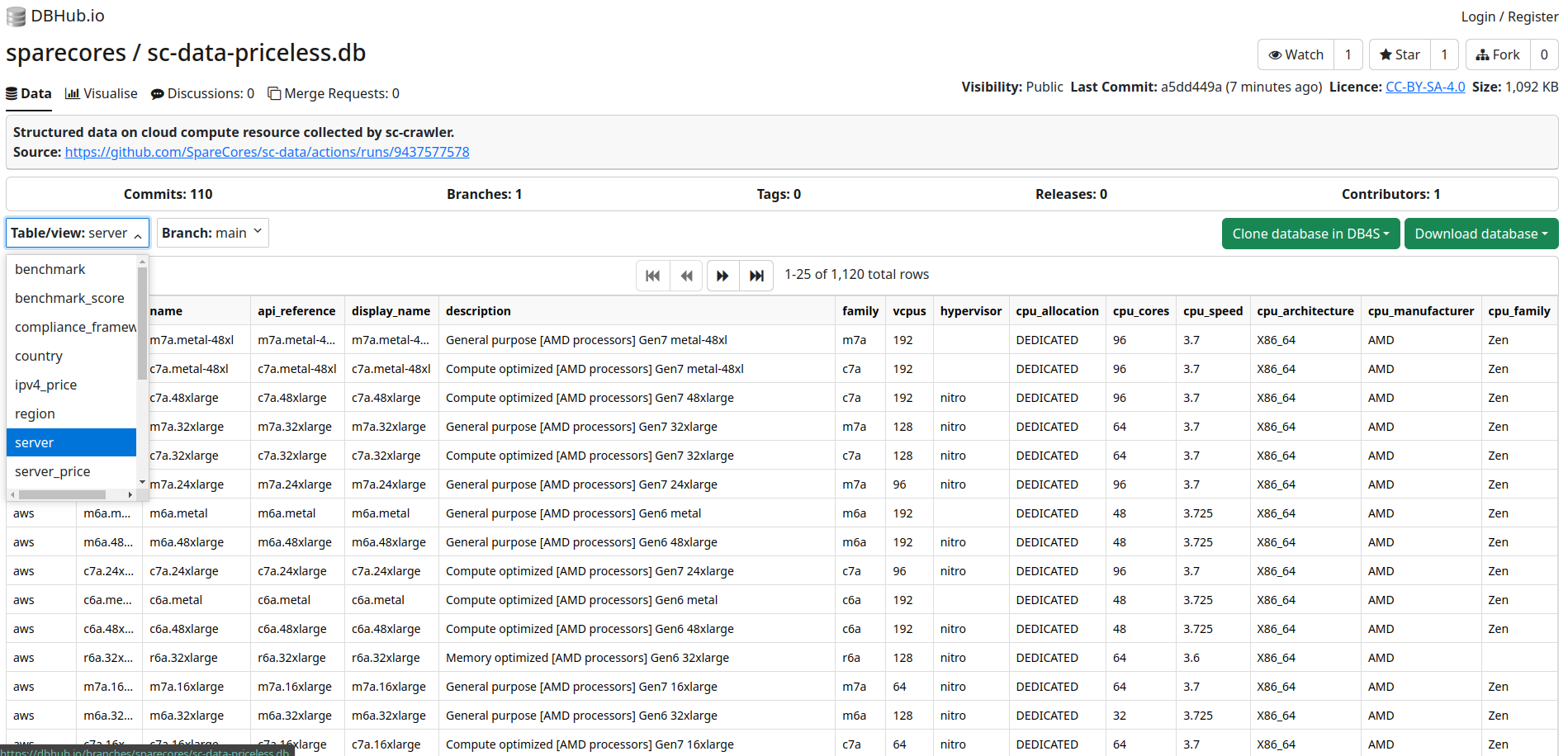
Source: dbhub.io/sparecores
>>> from sparecores import team

@bra-fsn

@palabola

@daroczig
>>> from sparecores import team
@bra-fsn
Infrastructure and Python veteran.
@palabola
Guardian of the front-end and Node.js tools.
@daroczig
Hack of all trades, master of NaN.