
We had been planning to benchmark the prompt processing and text generation speeds of various LLMs for some time, especially after our acceptance into the NVIDIA Inception Program. The final push came with the announcement of the Kubernetes Community Days (KCD) in Budapest. We submitted a talk proposal promising to benchmark inference speeds on over 2000 cloud servers, which was accepted! This motivated us to accelerate our related work at last to meet the deadline.
This article offers a technical overview of some of our related design decisions and the implementation details. But if you're here for the numbers, some of our highlights:
- No one-size-fits-all: There is no single instance type that is the optimal choice for all LLM serving needs. Depending on the LLM size and task (e.g. prompt processing VS text generation), different server options deliver the fastest speed and highest cost-efficiency.
- Performance vs. Cost Trade-off: While NVIDIA GPUs generally provide significantly higher performance due to CUDA optimization, CPU-only servers can sometimes be more cost-efficient, especially when considering the aggregate performance of multiple cheaper instances compared to a few expensive GPU servers.
- Multi-GPU Utilization Challenges: Despite advancements in LLM serving frameworks, effectively utilizing multiple GPUs on a single server remains challenging. While beneficial for large models that require multiple GPUs to fit all layers into VRAM, smaller models don't scale performance significantly across multiple GPUs.
If you're primarily interested in the benchmark data and further analysis rather than the technical details, feel free to skip ahead to the Results.
Infrastructure #
We already had the core infrastructure in place to run containerized benchmarks on any or all of our ~2300 supported cloud server configurations:
- Pulumi templates
(in our
sc-runnerrepo) to provision and tear down servers and the related storage, network environment, etc. - Multi-architecture Docker images built via GitHub Actions in our
sc-imagesrepository. - Task definitions in our
sc-inspectorPython module to orchestratesc-runner. - Raw-result storage in the open, copyleft-licensed
sc-inspector-datarepo. - ETL & publishing via the open-source
sc-crawlerPython package into our copyleft-licensedsc-datarepository.
With all this in place, the next steps seemed straightforward:
- Build a new Docker image in
sc-images. - Add a few lines of task definition to
sc-inspector. - Configure
sc-crawlerto structure and publish the data tosc-data.
And that should have been it ... well, almost.
Serving LLMs in a Heterogeneous Environment #
The primary challenge was serving LLMs across a highly heterogeneous environment, ranging from tiny machines with less than 1GB of RAM to high-end servers featuring terabytes of memory, hundreds of CPU cores, and sometimes multiple powerful GPUs from various manufacturers with differing drivers.
Our initial search focused on an LLM serving framework capable of running
inference on both CPUs and GPUs with minimal fine-tuning, ensuring compatibility
across all our supported cloud servers. After evaluating several candidates, we
settled on Georgi Gerganov's excellent llama.cpp. This lightweight and
high-performant inference engine for large language models, written in C and
C++, offers several key advantages:
- It supports both CPU and GPU inference.
- It benefits from a very active development community, is constantly improving, and is widely adopted.
- It features a robust CI/CD pipeline that builds container images for multiple
architectures, including
x86_64andARM64, along with a CUDA-enabled build. - It utilizes GGML, providing optimized builds for a wide range of CPU microarchitectures (e.g., from Intel Sandy Bridge to Sapphire Rapids).
- It includes a configurable benchmarking script (
llama-bench) for measuring inference speed across repeated text generation or prompt processing runs.
While llama.cpp provides separate Docker images for CPU and CUDA support, our
goal was to deliver a unified container image compatible with all target
architectures.
To accomplish this, we created a new image that bundles both the CPU and CUDA
binaries, and extracts the necessary
shared libraries from their respective base images.
We also added a lightweight wrapper script to
automatically select the appropriate backend at runtime.
Large Language Models #
To ensure a comprehensive benchmark, we selected a diverse set of widely used LLMs, varying in size and capabilities:
| Model | Parameters | File Size |
|---|---|---|
| SmolLM-135M.Q4_K_M.gguf | 135M | 100MB |
| qwen1_5-0_5b-chat-q4_k_m.gguf | 500M | 400MB |
| gemma-2b.Q4_K_M.gguf | 2B | 1.5GB |
| llama-7b.Q4_K_M.gguf | 7B | 4GB |
| phi-4-q4.gguf | 14B | 9GB |
| Llama-3.3-70B-Instruct-Q4_K_M.gguf | 70B | 42GB |
We used quantized versions of each model, which significantly reduce memory usage and load times. The models ranged in size from around 100 million to 70 billion parameters.
Starting each machine from a clean state required downloading our combined container image (~7 GB) and then the selected models (~60 GB). This meant benchmarks needed to run on machines with at least 75 GB of disk space.
Keeping costs under control was also crucial. For example, downloading the largest model (~42 GB) on a small machine with limited bandwidth could take over an hour and eventually fail due to memory constraints.
To mitigate this, we implemented a background thread downloading the models sequentially, prioritized by size. Once a model was downloaded, we marked it as ready for benchmarking in the main thread. Models were then evaluated in sequence, with early termination if inference speed fell below a predefined threshold. If the next model in line was likely to exceed bandwidth or performance limits, the process was halted to avoid unnecessary cost.
Cost Control #
These thresholds we applied were dynamic, depending on the task (prompt processing or text generation) and the token length of the input or output. For instance, a throughput of 1 token per second might be acceptable for generating short responses, but it would be impractical for batch processing 32k-token inputs, where a minimum of 1,000 tokens per second is more appropriate. This adaptive strategy allowed us to optimize runtime and control costs across diverse workloads.
By applying these constraints, we were able to keep the overall budget for starting 2000+ servers under $10k — at least in theory. We ended up with the following cost breakdown per vendor:
| Vendor | Cost |
|---|---|
| AWS | 2153.68 USD |
| GCP | 696.9 USD |
| Azure | 8036.71 USD |
| Hetzner | 8.65 EUR |
| Upcloud | 170.21 EUR |
In practice, we spent well over $10k on this project. We experienced unexpected costs at Azure due to instances not being terminated as expected, but fortunately, these were covered by generous cloud credits from vendors. We are grateful for their support!
Coverage and Limitations #
We managed to successfully run the benchmarks on 2,106 cloud servers out of the currently tracked 2,343 servers across five vendors (as of April 30, 2025), spanning various CPU architectures and configurations:
[sc-inspector-data]$ find . -name meta.json -path "*llm*" | \
xargs jq -cr 'select(.exit_code == 0)' | \
wc -l
2106
While we continue to evaluate the remaining ~235 server types, full coverage is unlikely due to the following reasons:
- Quota limits imposed by vendors (see our debug page for per-vendor details).
- Insufficient memory (less than 1 GiB) to load even the smallest model.
- Limited storage (less than 75 GiB) that cannot be easily extended (e.g., cloud server plans with fixed disk size).
- Deprecation of server types by the vendor.
It's also worth noting that although llama.cpp successfully ran on most
servers, performance was not always optimal. For example:
- Non-NVIDIA GPUs could not be used for inference due to lack of CUDA compatibility.
- Some NVIDIA cards (e.g. T4G) were also incompatible due to driver issues.
In such cases, the LLM inference speed benchmarks defaulted to CPU execution.
Finally, although llama.cpp can utilize multiple GPUs, this primarily benefits
larger LLMs to load all layers into VRAM. Smaller models that easily fit on a
single GPU's memory do not significantly benefit from having multiple GPUs. To
potentially improve this, we could extend the current implementation to start
multiple instances of the benchmarking script on the same machine, e.g. one for
each GPU. However, as this would involve significant heuristics and complexity,
we decided to keep the approach simple (and more reliable) for now.
Results #
Overall, we evaluated more than 2000 servers and ran prompt processing and text generation tasks using 1-6 LLMs (depending on the available amount of memory or VRAM) with various token lengths and input/output sizes, resulting in almost 75k data points.
To count how many servers could successfully run each model, we queried our live database dump (36 MB SQLite file):
WITH models as (
SELECT DISTINCT vendor_id, server_id, json_extract(config, '$.model') AS model
FROM benchmark_score
WHERE benchmark_id LIKE 'llm_%')
SELECT model, COUNT(*)
FROM models
GROUP BY 1
ORDER BY 2 DESC;
Results as of April 30, 2025:
| model | COUNT(*) |
|---|---|
| SmolLM-135M.Q4_K_M.gguf | 2086 |
| qwen1_5-0_5b-chat-q4_k_m.gguf | 1962 |
| gemma-2b.Q4_K_M.gguf | 1883 |
| llama-7b.Q4_K_M.gguf | 1713 |
| phi-4-q4.gguf | 1448 |
| Llama-3.3-70B-Instruct-Q4_K_M.gguf | 1229 |
Thus, depending on your LLM inference needs, the number of viable server options might be limited — but still having over 1,000 cloud server types for the largest (70B) model.
Case Study: Phi 4 #
As an example, let's take a look at the results for the phi-4-q4.gguf model
with 14B parameters. We filtered for servers that achieved at least 50 tokens
per second in prompt processing of 512-token inputs:
SELECT * FROM benchmark_score
WHERE
benchmark_id = 'llm_speed:prompt_processing'
AND json_extract(config, '$.model') = 'phi-4-q4.gguf'
AND json_extract(config, '$.tokens') = 512
AND score >= 50
ORDER BY score DESC;
This returned around 600 servers, ranging from:
- Fastest: 4,768 tokens/sec (AWS
g6efamily with NVIDIA L40S GPUs) - Slowest: Just over the provided threshold, using CPU only.
Price-Performance Analysis #
Calculating the performance for the price requires us to join the server_price
table. For example, considering the best on-demand server price:
WITH scores AS (
SELECT vendor_id, server_id, score
FROM benchmark_score
WHERE
benchmark_id = 'llm_speed:prompt_processing'
AND json_extract(config, '$.model') = 'phi-4-q4.gguf'
AND json_extract(config, '$.tokens') = 512
AND score >= 500),
prices AS (
SELECT vendor_id, server_id, MIN(price) AS price
FROM server_price
WHERE allocation = 'ONDEMAND'
GROUP BY 1, 2)
SELECT
scores.vendor_id AS vendor, api_reference AS server,
vcpus, memory_amount / 1024 AS memory, gpu_count AS gpus, gpu_model,
ROUND(score, 2) AS score, price, ROUND(score / price, 2) AS score_per_price
FROM scores
LEFT JOIN prices USING (vendor_id, server_id)
LEFT JOIN server USING (vendor_id, server_id)
ORDER BY score_per_price DESC
LIMIT 10;
This returns the following top 10 servers on April 30, 2025:
| vendor | server | vcpus | memory | gpus | gpu_model | score | price | score_per_price |
|---|---|---|---|---|---|---|---|---|
| gcp | g2-standard-4 | 4 | 16 | 1 | L4 | 1194.57 | 0.14631 | 8164.64 |
| gcp | g2-standard-8 | 8 | 32 | 1 | L4 | 1137.47 | 0.29262 | 3887.2 |
| gcp | a2-highgpu-1g | 12 | 85 | 1 | A100 | 2468.31 | 0.73948 | 3337.9 |
| gcp | g2-standard-12 | 12 | 48 | 1 | L4 | 1162.21 | 0.43893 | 2647.82 |
| aws | g6e.xlarge | 4 | 32 | 1 | L40S | 4660.96 | 1.861 | 2504.54 |
| gcp | a2-ultragpu-1g | 12 | 170 | 1 | A100 | 2475.82 | 1.09962 | 2251.52 |
| aws | g6e.2xlarge | 8 | 64 | 1 | L40S | 4677.89 | 2.24208 | 2086.4 |
| gcp | g2-standard-16 | 16 | 64 | 1 | L4 | 1117.46 | 0.58525 | 1909.36 |
| aws | g5.xlarge | 4 | 16 | 1 | A10G | 1887.03 | 1.006 | 1875.77 |
| gcp | a2-highgpu-2g | 24 | 170 | 2 | A100 | 2469.94 | 1.47895 | 1670.06 |
In this scenario, the smallest GPU options are the most cost efficient: with a single GPU, minimal CPU and irrelevant memory amount as data are stored in the VRAM anyway.
The computed score_per_price shows how much inference speed you can buy with
1 USD/hour. The most cost-effective option from the above table suggests that a
g2-standard-4 costs $0.14631/hour, so we could get almost 7 servers for 1
USD/hour, providing 8164+ tokens/second overall inference speed, which
translates to ~3.4 US cents per 1M tokens when fully utilized.
The next best option (g2-standard-8) provides the same performance as equipped
with the same GPU, which is doing all the work independently of the extra CPU
cores or memory amount, so the cost efficiency is about half of the first
one due to the doubled costs, with identical throughput.
Visual Exploration #
If you might prefer a more intuitive way of getting access to this data, look no
further: this is easily accessible from our Server Navigator!
Just select the preferred LLM inference speed benchmark instead of the default
stress-ng at the top of the table, as e.g. in the below screenshot:
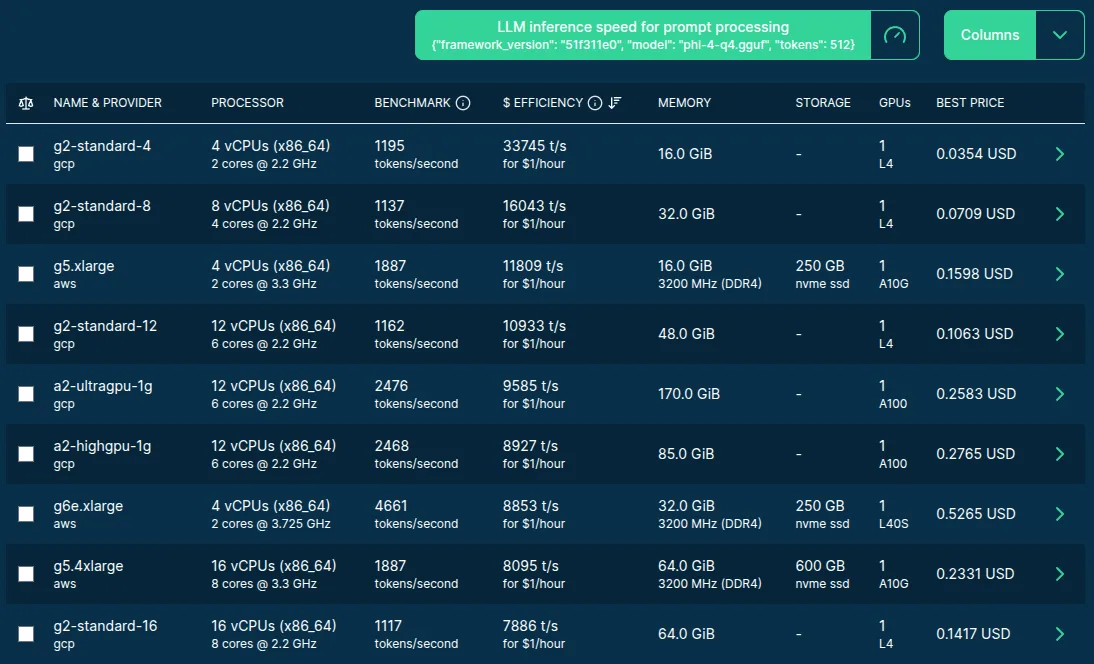
Image source: Spare Cores server listing.
Clicking on a row will take you to the server details page, including all the
LLM inference speed results that are also embedded below for the above-mentioned
g2-standard-4 server as interactive charts:
You might wonder now if it is the best server for all LLM needs? As usual, it depends.
Model Size Impacts #
If you need to serve smaller models fitting in the VRAM of a
g2-standard-4, it is an excellent choice, but if you serve larger models, you
might need more powerful GPU options, or go with the much cheaper CPU-only
servers. Another similar example using the 70B model for text generation:
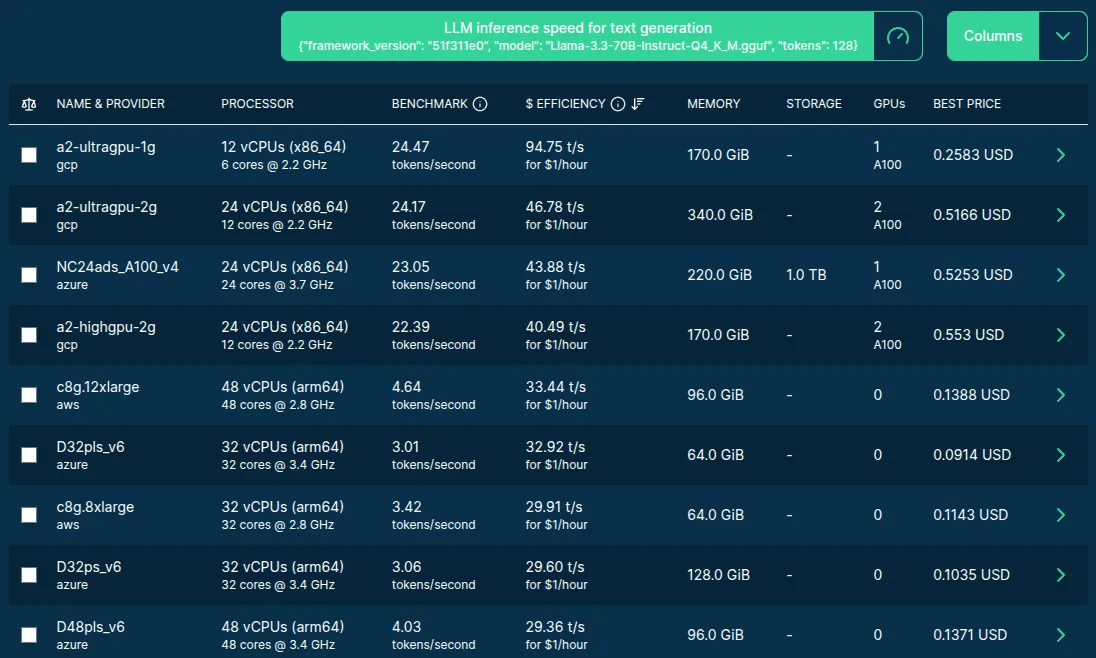
Image source: Spare Cores server listing.
In this case, GPUs with more memory are required to load all layers into VRAM, so the most cost-efficient options are the cheapest instances with an A100 GPU.
Although the CPU-only options are much less performant (a single A100 delivers 20+ tokens/second, while 32 vCPUs provide overall 3-4 tokens/second), there are many much cheaper servers are still available, providing a good cost efficiency as well — as you can see in the above table.
Looking at the smallest LLM model:
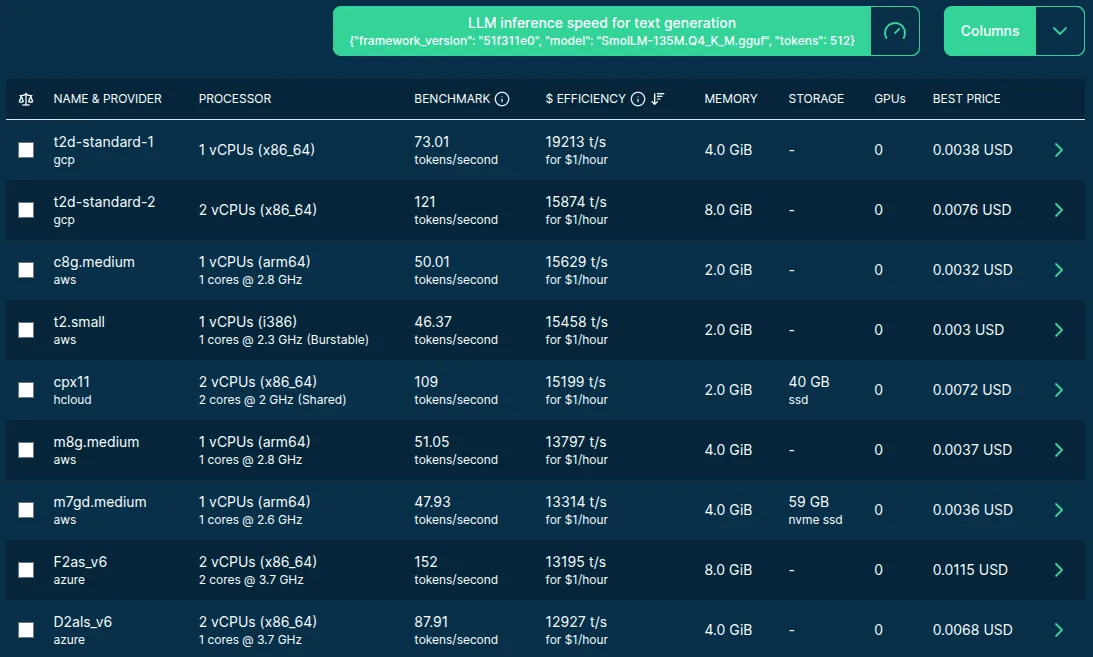
Image source: Spare Cores server listing.
In this case, it's clear that the winners are the cheapest tiny servers.
Comparing Servers for LLM Inference #
Finally, let's compare the winners of this last listing as an example of our Compare Guide:
You can quickly evaluate how these small machines perform against the larger models by using the dropdown of the above interactive chart.
Next Steps #
We hope that these benchmarks help you make an informed decision when choosing the right server type(s) for your LLM serving use case! If you have any questions, concerns, or suggestions, please leave a message in the comment section below, or schedule a call with us to discuss your needs.