
Since the project's inception, one of the most common feature requests has been to allow users to search and sort servers by any benchmark score, not only the default stress-ng multi-core CPU score that we use as our standard SCore (you can read more details about this latter in the "One SCore to Rule Them All" section of our "Unlocking Cloud Compute Performance" article).
As a frequent user of our own site (dogfooding rocks!), I completely understood and related to this request, but was also worried about the database and backend performance implications of such a feature, so it was delayed for a while. Now I'm super excited to announce that it was finally implemented without any noticeable performance impact!
Frontend Updates #
The most noticeable change on the server search page is the addition of a "Select Benchmark" dropdown above the search results table:
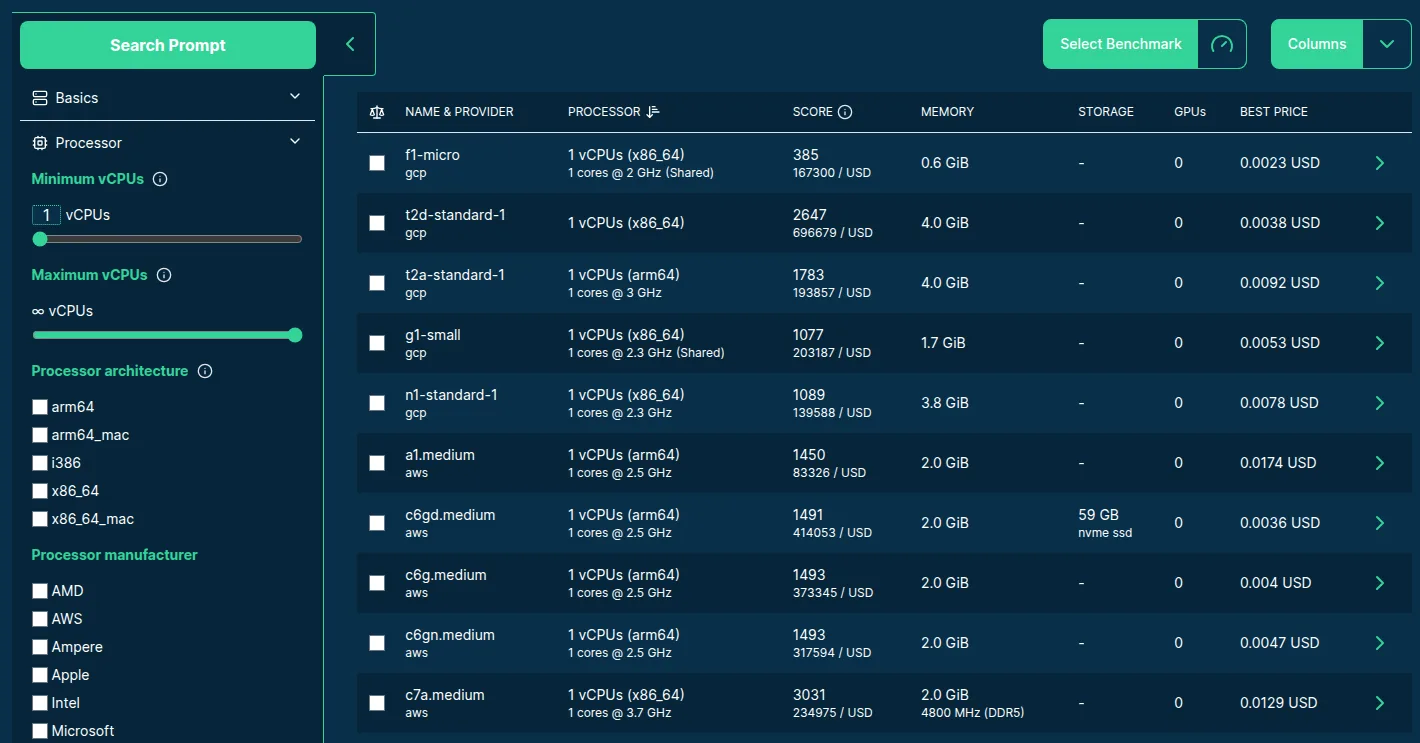
Updated Server search with the "Select Benchmark" button
Clicking the "Select Benchmark" button opens a modal window with the list of benchmark categories and then subcategories after selecting one — letting you access over 500 benchmark scores:
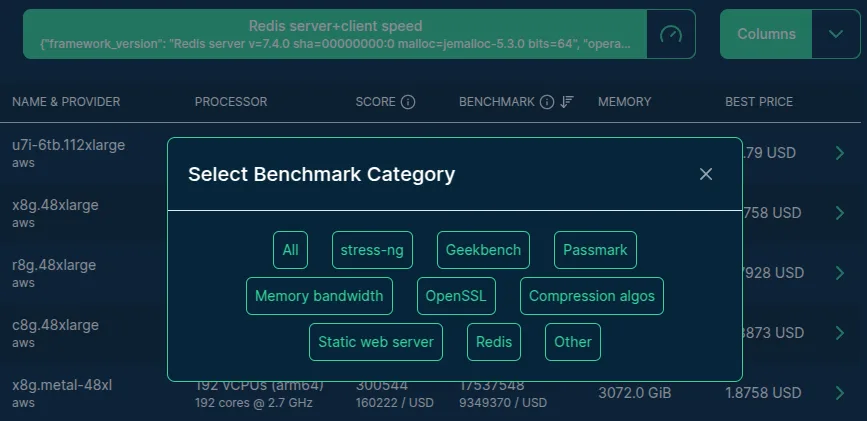
List of available benchmark categories
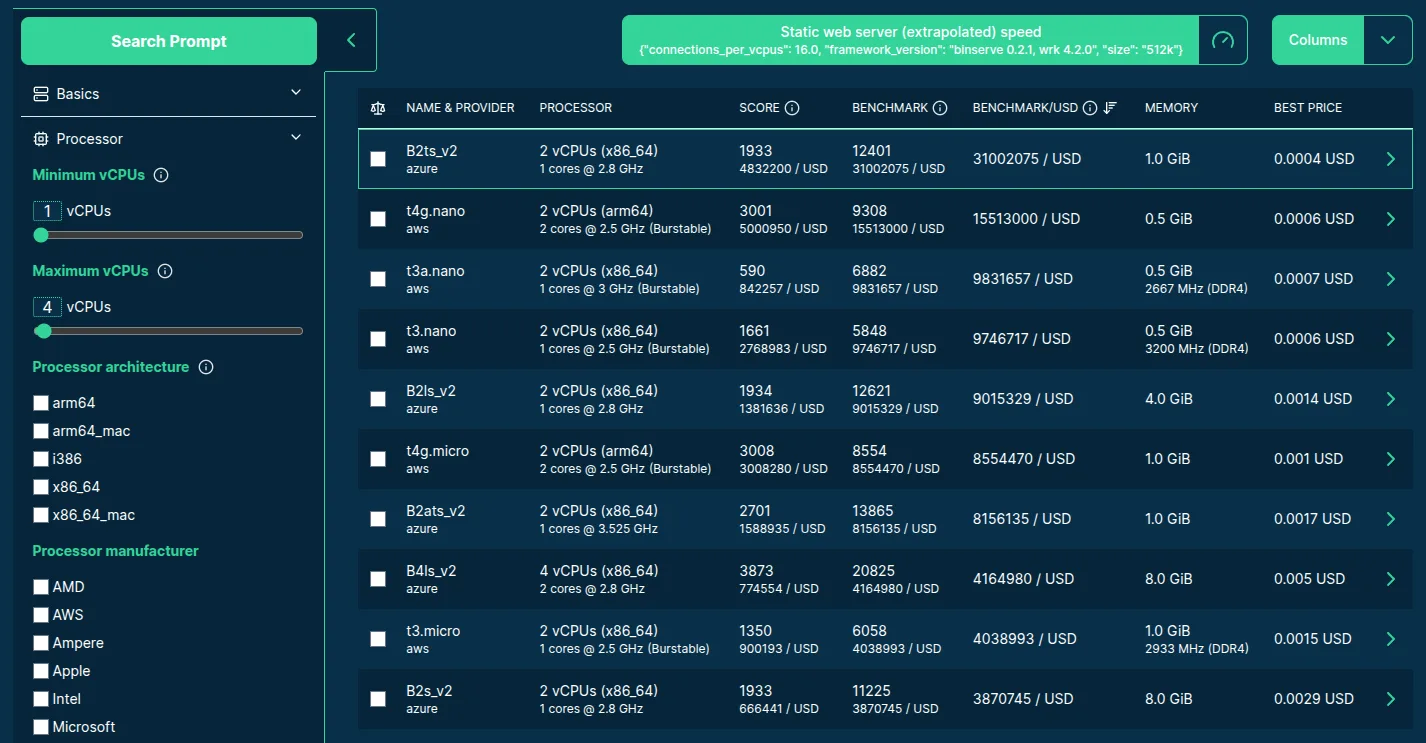
After selecting a benchmark, the "BENCHMARK" column is automatically added to the table with the following two lines:
- The selected benchmark's raw score for the server.
- The benchmark score you get for 1 USD, so the raw score divided by the best available (usually spot) hourly server price.
Clicking on the "BENCHMARK" column header will toggle sorting the table by the selected benchmark score between ascending and descending order. If you want to sort by performance/price ratio, you can enable the related column and then click on the "BENCHMARK/USD" column header. See for example the list of max 4 vCPU servers sorted by the highest static web serving (extrapolated) speed you can get for a dollar — potentially reaching over 30M requests with a 512kB response size per second with lots of B2ts_v2 servers:
And of course, you can compare any number of selected servers with much more details by marking the related checkboxes in the table and then clicking on the "Compare" button. An example chart embedded from that page for static web serving on three hyperscaler servers:
You can learn more about this feature on our Compare Servers page.
Backend Improvements #
Though less visible, the backend enhancements are potentially even more powerful, providing the main support for all the aforementioned frontend features: you can also make Keeper queries to sort and filter the servers by any benchmark score.
The technical challenge of this feature involved extending the order_by parameter to accommodate the new columns, so the backend needed to know all 500+ benchmark scores for the 2000+ servers along with the best hourly prices for each server type, potentially recorded in different currencies.
This is a relatively large lookup table after all the joins, for which a full table scan was not an option: early tests timed out after minutes on a 4 GiB RAM dev container, writing GBs of temporary tables to the disk.
So we needed to find a way to optimize the query, keeping in mind that the Keeper's database is a static SQLite file by default:
- First, we decided to pre-compute the best price for each server in USD and cache for 10 minutes as part of our extended
server_extra~materialized view. This simplified the query significantly so that we don't need to always join and sort at all the 300k+ rows of theserver_pricestable along with the most recent currency rates. - Then, we introduced indexes on the related tables, added at the time of the server start and database updates (every 10 minutes).
- And finally, we reviewed how we run the extra query to count the total number of matching records despite paging, which data is added as an optional header to the Keeper response, so that the frontend can render a nice pager without extra queries.
We also experimented with DuckDB, which performed extremely well with the most complex queries (especially counting rows) at the cost of relatively high memory usage, but was rather slow compared to SQLite for the simpler lookups, so we went back to SQLite with pre-computed and periodically updated indexes.
Feedback #
We're super excited to see many of you using this feature. Please share your feedback or suggestions in the comment box below!