
It has been a busy year so far, and I realized I had never sat down to write a proper update on everything that has been happening at Spare Cores. Consider this a catch-up post: new vendor integrations, a large benchmarking effort, two new open-source packages, and more conference talks than we originally planned. Here is a summary of what we have been building and doing since the start of 2025.
February: UpCloud Joins the Family #
We started the year by adding our fifth cloud vendor thanks to an inbound request. UpCloud now lists 67 server types in Spare Cores, complete with hardware specs and benchmark data. The integration was a collaborative effort -- UpCloud provided generous cloud credits and extended our quotas, which meant we could benchmark all their server types, including the largest node with 80 vCPUs and 512 GiB of RAM!
The most interesting finding: UpCloud's Cloud Native plans offer a very good performance/price ratio for encryption, compression, and memory-heavy workloads, especially because their pricing includes egress traffic and an IPv4 address -- extras that add real cost with most other providers.
March: Search by Benchmark #
Since the project's inception, the most common feature request we received was the ability to sort servers by any benchmark score, not just the default stress-ng CPU score. We finally shipped it in March.
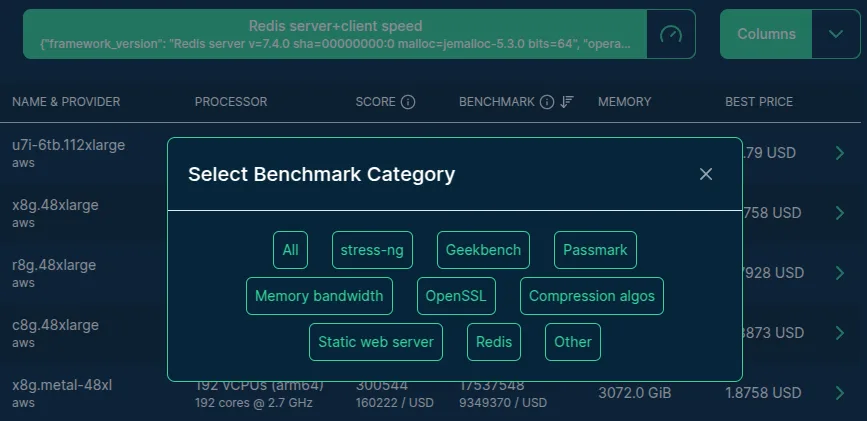
List of available benchmark categories
The new benchmark selector lets you pick from over 500 benchmark scores and sort or filter servers by raw score or by score-per-dollar. The backend work was the harder part: the naive approach timed out after minutes, writing gigabytes of temp tables to disk. We ended up pre-computing best prices per server, adding targeted indexes, and revisiting how we count paginated rows. The result is fast enough that we are not embarrassed by it.
April: The Resource Tracker #
This was probably the most significant release of the year. We shipped the resource-tracker Python package -- a tool that monitors the CPU, memory, GPU, disk, and network usage of a process and its descendants, then recommends the cheapest cloud server that meets those requirements using the Spare Cores Navigator data.
The initial procfs implementation was quick to put together, but only worked on Linux. Thanks to inbound requests, we added a psutil fallback that made it work on macOS and Windows as well, which matters because data scientists often develop locally and deploy to cloud.
The Metaflow integration came in the same release: add a single @track_resources decorator to any step and you get a full resource usage card with cloud recommendations in your Metaflow run report. Thanks to Ville Tuulos from Outerbounds for the early conversation that pushed us to prioritize this.

Also in April: we attended KCD Budapest 2025, where we presented the LLM inference benchmarks (more on that below). First Kubernetes-focused conference for us -- a good crowd.

May: LLM Inference Speed on 2000+ Servers #
The KCD Budapest talk deadline was the final push to ship something we had been planning for a long time: benchmarking LLM inference speed across the full Spare Cores server catalogue.
We ran llama.cpp on 2,106 out of 2,343 tracked servers, benchmarking six models from SmolLM-135M up to Llama-3.3-70B, for a total of almost 75k data points:
| Model | Parameters | File Size |
|---|---|---|
| SmolLM-135M.Q4_K_M.gguf | 135M | 100MB |
| qwen1_5-0_5b-chat-q4_k_m.gguf | 500M | 400MB |
| gemma-2b.Q4_K_M.gguf | 2B | 1.5GB |
| llama-7b.Q4_K_M.gguf | 7B | 4GB |
| phi-4-q4.gguf | 14B | 9GB |
| Llama-3.3-70B-Instruct-Q4_K_M.gguf | 70B | 42GB |
The infrastructure challenge was real -- a single Docker image that works across CPU-only servers, NVIDIA GPUs, ARM64, and x86_64, with adaptive early termination to keep costs under control.
Honestly, we spent well over $10k on this project. Unexpected Azure termination issues pushed the Azure bill to over $8k alone, though vendor cloud credits covered it. The results are available on the Server Navigator, or embedded in any HTML page, see e.g. the below LLM inference speed chart for the prompt processing of the g2-standard-4 server:
The headline finding: there is no one-size-fits-all answer for LLM inference. For small models, cheap CPU-only servers win on cost efficiency. For larger models, a single mid-range GPU (GCP g2-standard-4 with an L4) is remarkably cost-effective at around $0.15/hour.
June and September: Conference Season #
We attended the Budapest Data+ML Forum in June, then in late summer traveled to three more events:
- useR! 2025 (Durham, NC, USA),
- PyData Berlin 2025 (Germany),
- PyData Amsterdam 2025 (the Netherlands).
At all three we presented the Resource Tracker and the LLM inference benchmarks. The useR! talk was a good opportunity to show what the Resource Tracker looks like when driven from R rather than Python -- and it prompted us to finish the R package.






August: Resource Tracker for R #
Speaking of which: we shipped native R support for the Resource Tracker in August. The R package wraps the Python implementation via reticulate, so the Python side still does the heavy lifting, but R users interact with it entirely through R6 classes without touching Python directly.
For me personally, bringing this to R felt like closing a loop. I have been maintaining R packages for well over a decade and have managed infrastructure for mixed-language data science teams. The question "how much RAM did that model training actually use, and what is the cheapest server I should run it on next time?" now has a clean answer in R.
Behind the Scenes #
Honestly, looking at that list of releases above, I should mention the context in which they happened.
The NGI Search grant that funded the initial Spare Cores work wrapped up by the end of 2024. With it went the dedicated developer team we had in place during the grant period, so for most of 2025, Spare Cores has been a one-person shop -- which means that most of the work on the UpCloud integration, the benchmark selector, the Resource Tracker, the LLM benchmarks, and the R package were all built by essentially one person, which probably explains why things sometimes took longer than I would have liked.
We wrote separately about the difficult situation with NGI Search funding in the EU, which is a broader problem affecting many open-source projects, not just ours.
What's Coming #
We have been quiet on the blog for the past couple of months, but not because nothing is happening -- quite the opposite. There are some exciting things in the works that we are not ready to share just yet, but we will have news soon. Stay tuned.